






SQL Indexes Explained
Properly used, an SQL database index can be so effective that it might seem like magic. But the following series of exercises will show that underneath, the logic of most SQL indexes—and wielding them correctly—is quite straightforward.
In this series, SQL Indexes Explained, we will walk through the motivations for using indexes to access data and for designing indexes in the way it is done by all modern RDBMSes. We will then look at the algorithms used to return data for specific query patterns.
You don’t have to know much about indexes to be able to follow SQL Indexes Explained. There are just two preconditions:
- Basic SQL knowledge
- Basic knowledge of any programming language
The main topics SQL Indexes Explained will get into are:
- Why we need SQL database indexes; visualizing execution plans using indexes
- Index design: which indexes make a query fast and efficient
- How we can write a query to effectively use indexes
- The impact of the use of indexes in SQL on read/write efficiency
- Covering indexes
- Partitioning, its impact on reading and writing, and when to use it
This isn’t just an SQL index tutorial—it’s a deep dive into understanding the underlying mechanics of indexes.
We are going to figure out how an RDBMS uses indexes by doing exercises and analyzing our problem-solving methods. Our exercise material consists of read-only Google Sheets. To do an exercise, you can copy the Google Sheet (File → Make a copy) or copy its contents into your own Google Sheet.
In every exercise, we’ll show an SQL query that uses Oracle syntax. For dates, we will use the ISO 8601 format, YYYY-MM-DD.
Exercise 1: All of a Client’s Reservations
The first task—don’t do it just yet—is to find all rows from the Reservation spreadsheet for a specific client of a hotel reservation system, and copy them into your own spreadsheet, simulating the execution of the following query:
SELECT
*
FROM
Reservations
WHERE
ClientID = 10;
But we want to follow a particular method.
Approach 1: No Sorting, No Filtering
For the first try, do not use any sorting or filtering features. Please, record the time spent. The resulting sheet should contain 73 rows.
This pseudocode illustrates the algorithm for accomplishing the task without sorting:
For each row from Reservations
If Reservations.ClientID = 10 then fetch Reservations.*
In this case, we had to check all 841 rows to return and copy 73 rows satisfying the condition.
Approach 2: Sorting Only
For the second try, sort the sheet according to the value of the ClientID column. Do not use filters. Record the time and compare it with the time it took to complete the task without sorting data.
After sorting, the approach looks like this:
For each row from Reservations
If ClientID = 10 then fetch Reservations.*
Else if ClientID > 10 exit
This time, we had to check “only” 780 rows. If we could somehow jump to the first row, it would take even less time.
But if we would have to develop a program for the task, this solution would be even slower than the first one. That’s because we would have to sort all the data first, which means each row would have to be accessed at least once. This approach is good only if the sheet is already sorted in the desired order.
Exercise 2: The Number of Reservations Starting on a Given Date
Now the task is to count the number of check-ins on the 16th of August 2020:
SELECT
COUNT (*)
FROM
Reservations
WHERE
DateFrom >= TO_DATE('2020-08-16','YYYY-MM-DD')
AND DateFrom < TO_DATE('2020-08-17','YYYY-MM-DD');
Use the spreadsheet from Exercise 1. Measure and compare the time spent completing the task with and without sorting. The correct count is 91.
For the approach without sorting, the algorithm is basically the same as the one from Exercise 1.
The sorting approach is also similar to the one from the previous exercise. We will just split the loop into two parts:
-- Assumption: Table reservation is sorted by DateFrom
-- Find the first reservation from the 16th of August 2020.
Repeat
Read next row
Until DateFrom >= '2020-08-16'
-- Calculate the count
While DateFrom < '2020-08-17'
Increase the count
Read the next row
Exercise 3: Criminal Investigation
The police inspector requests to see a list of guests that arrived at the hotel on the 13th and 14th of August 2020.
SELECT
ClientID
FROM
Reservations
WHERE
DateFrom >= TO_DATE('2020-08-13','YYYY-MM-DD')
AND DateFrom < TO_DATE('2020-08-15','YYYY-MM-DD')
AND HotelID = 3;
Approach 1: Sorted by Date Only
The inspector wants the list fast. We already know that we’d better sort the table/spreadsheet according to the date of arrival. If we just finished Exercise 2, we are lucky that the table is already sorted. So, we apply the approach similar to the one from Exercise 2.
Please, try and record the time, the number of rows you had to read, and the number of items on the list.
-- Assumption: Table reservation is sorted by DateFrom
-- Find the first reservation from the 13th of August 2020.
Repeat
Read next row
Until DateFrom >= '2020-08-13'
-- Prepare the list
While DateFrom < '2020-08-15'
If HotelID = 3 then write down the ClientID
Read the next row
Using this approach, we had to read 511 rows to compile a list of 46 guests. If we were able to precisely slide down, we did not actually have to perform 324 reads from the repeat cycle just to locate the first arrival on the 13th of August. However, we still had to read more than 100 rows to check if the guest arrived in the hotel with a HotelID of 3.
The inspector waited all that time but would not be happy: Instead of guests’ names and other relevant data, we only delivered a list of meaningless IDs.
We’ll get back to that aspect later in the series. Let’s first find a way to prepare the list faster.
Approach 2: Sorted by Hotel, Then Date
To sort the rows according to HotelID then DateFrom, we can select all columns, then use the Google Sheets menu option Data → Sort range.
-- Assumption: Sorted according to HotelID and DateFrom
-- Find the first reservation for the HotelID = 3.
Repeat
Read next row
Until HotelID >= 3
-- Find the first arrival at the hotel on 13th of August
While HotelID = 3 and DateFrom < '2020-08-13'
Read the next row
-- Prepare the list
While HotelID = 3 and DateFrom < '2020-08-15'
Write down the ClientID
Read the next row
We had to skip the first 338 arrivals before locating the first one to our hotel. After that, we went over 103 earlier arrivals to locate the first on the 13th of August. Finally, we copied 46 consecutive values of ClientID. It helped us that in the third step, we were able to copy a block of consecutive IDs. Too bad we couldn’t somehow jump to the first row from that block.
Approach 3: Sorted by Hotel Only
Now try the same exercise using the spreadsheet ordered by HotelID only.
The algorithm applied to the table ordered by HotelID only is less efficient than when we sort by HotelID and DateFrom (in that order):
-- Assumption: Sorted according to HotelID
-- Find the first reservation for the HotelID = 3.
Repeat
Read next row
Until HotelID >= 3
-- Prepare the list
While HotelID = 3
If DateFrom >= '2020-08-13' and DateFrom < '2020-08-15'
Write down the ClientID
Read the next row
In this case, we have to read all 166 arrivals to the hotel with a HotelID of 3, and for each, to check if the DateFrom belongs to the requested interval.
Approach 4: Sorted by Date, Then Hotel
Does it really matter whether we sort first by HotelID and then DateFrom or vice versa? Let’s find out: Try sorting first by DateFrom, then by HotelID.
-- Assumption: Sorted according to DateFrom and HotelID
-- Find the first arrival on 13th of August
While DateFrom < '2020-08-13'
Read the next row
--Find the first arrival at the Hotel
While HotelID < 3 and DateFrom < '2020-08-15'
Read the next row
Repeat
If HotelID = 3
Write down the ClientID
Read the next row
Until DateFrom > '2020-08-14' or (DateFrom = '2020-08-14' and HotelID > 3)
We located the first row with the relevant date, then read more until we located the first arrival to the hotel. After that, for a number of rows, both conditions were fulfilled, the correct date and the right hotel. However, after arrivals in hotel 3, we had arrivals to hotels 4, 5, and so on, for the same date. After them, we had to again read rows for the next day for hotels 1 and 2, until we were able to read consecutive arrivals to our hotel of interest.
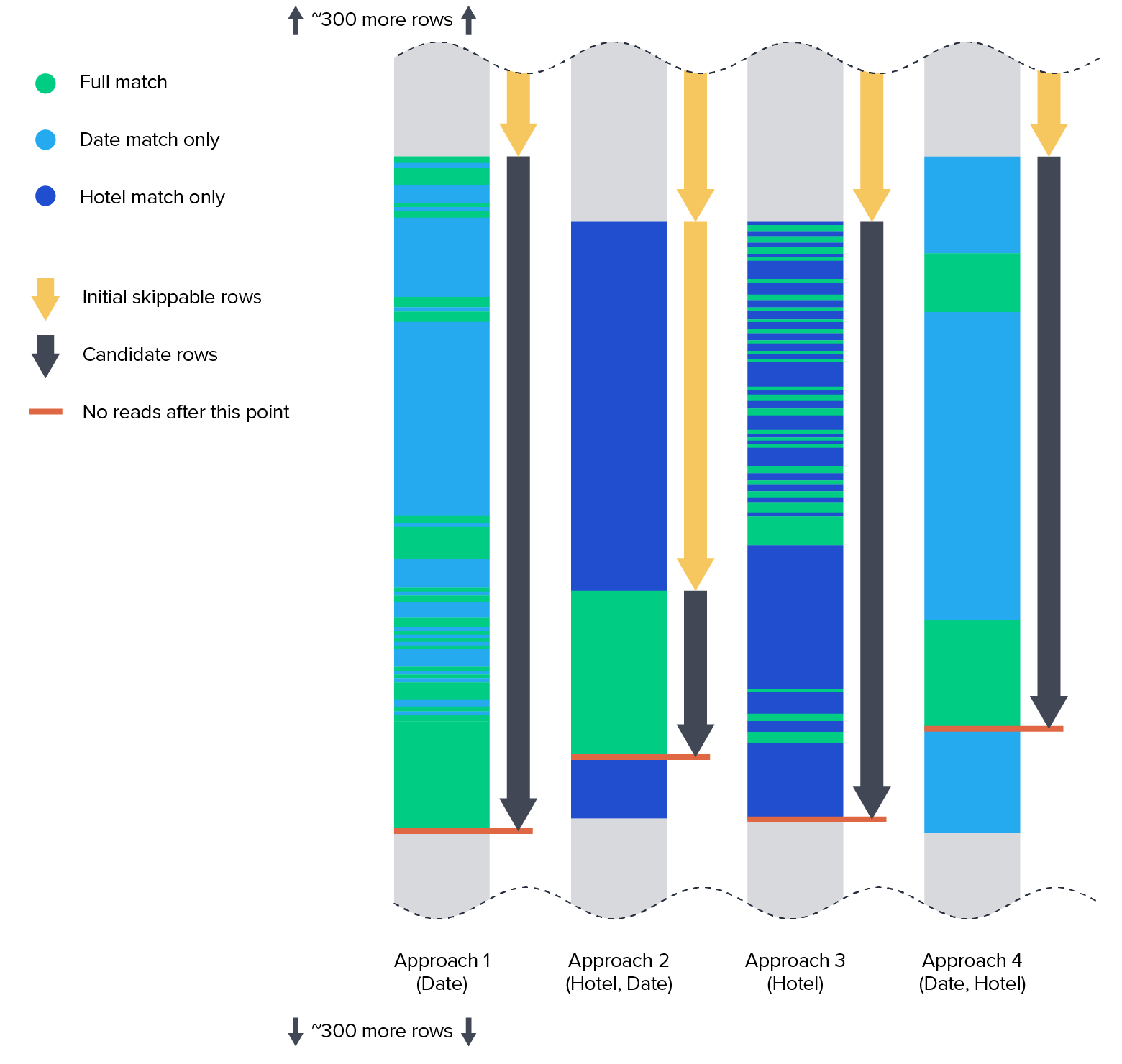
As we can see, all approaches have a single consecutive block of data in the middle of the complete set of rows, representing partially matched data. Approaches 2 and 4 are the only ones where logic allows us to stop the algorithm entirely before we reach the end of the partial matches.
Approach 4 has fully matched data in two blocks, but Approach 2 is the only one where the targeted data is all in one consecutive block.
| Approach 1 | Approach 2 | Approach 3 | Approach 4 | |
|---|---|---|---|---|
| Initial skippable rows | 324 | 338 + 103 = 441 | 342 | 324 |
| Candidate rows to examine | 188 | 46 | 166 | 159 |
| Skippable rows after algorithm stops | 328 | 353 | 332 | 357 |
| Total skippable rows | 652 | 794 | 674 | 681 |
By the numbers, it’s clear that Approach 2 has the most advantages in this case.
SQL Indexes Explained: Conclusions and What’s Next
Doing these exercises should make the following points become clear:
- Reading from a properly sorted table is faster.
- If a table is not already sorted, sorting takes more time than reading from an unsorted table.
- Finding a way to jump to the first row matching a search condition within the sorted table would save a lot of reads.
- It would be helpful to have a table sorted in advance.
- Maintaining the sorted copies of the table for the most frequent queries would be helpful.
Now, a sorted copy of a table sounds almost like a database index. The next article in SQL Indexes Explained will cover a rudimentary index implementation. Stay tuned with BrainSmiths Blogs !
Add comment